Neon Autoscaling is Generally Available
Manually resizing Postgres instances is a thing of the past

Neon autoscaling has officially graduated out of beta and is now available for all Neon databases, including the Free plan. With autoscaling enabled, your Neon Postgres databases automatically adjust CPU and memory based on workload, ensuring optimal performance and cost efficiency. This removes the need for manual server resizing and prevents budget waste from overprovisioning. Create a free Neon account and try it today.
Building autoscaling has been a main goal for Neon since we launched. A serverless experience for Postgres had to include a compute layer that scaled up and down automatically, including scaling down to zero when the database was not in use.
In most managed Postgres (RDS, Azure PG, Heroku, Supabase, Render) users have to size their CPU/memory in advance, estimating their peak and paying for this capacity 24/7 even if they only need it for a few hours a week. With autoscaling, Neon Postgres makes this manual experience obsolete.
The architectural foundations
Building autoscaling was no small feat. We faced many engineering challenges in building a solution reliable and robust enough for general availability, including kernel panics, I/O throttling, and a crucial issue involving communication stalls between Postgres instances and their safekeepers.
Our autoscaling algorithm is deeply integrated into the Neon architecture, which natively decouples storage and compute. In Neon, each Postgres instance operates within its own VM in a Kubernetes cluster. While Kubernetes traditionally uses containers, we opted for VMs to provide strong isolation boundaries, support dynamic resource adjustments, and enable seamless live migration.
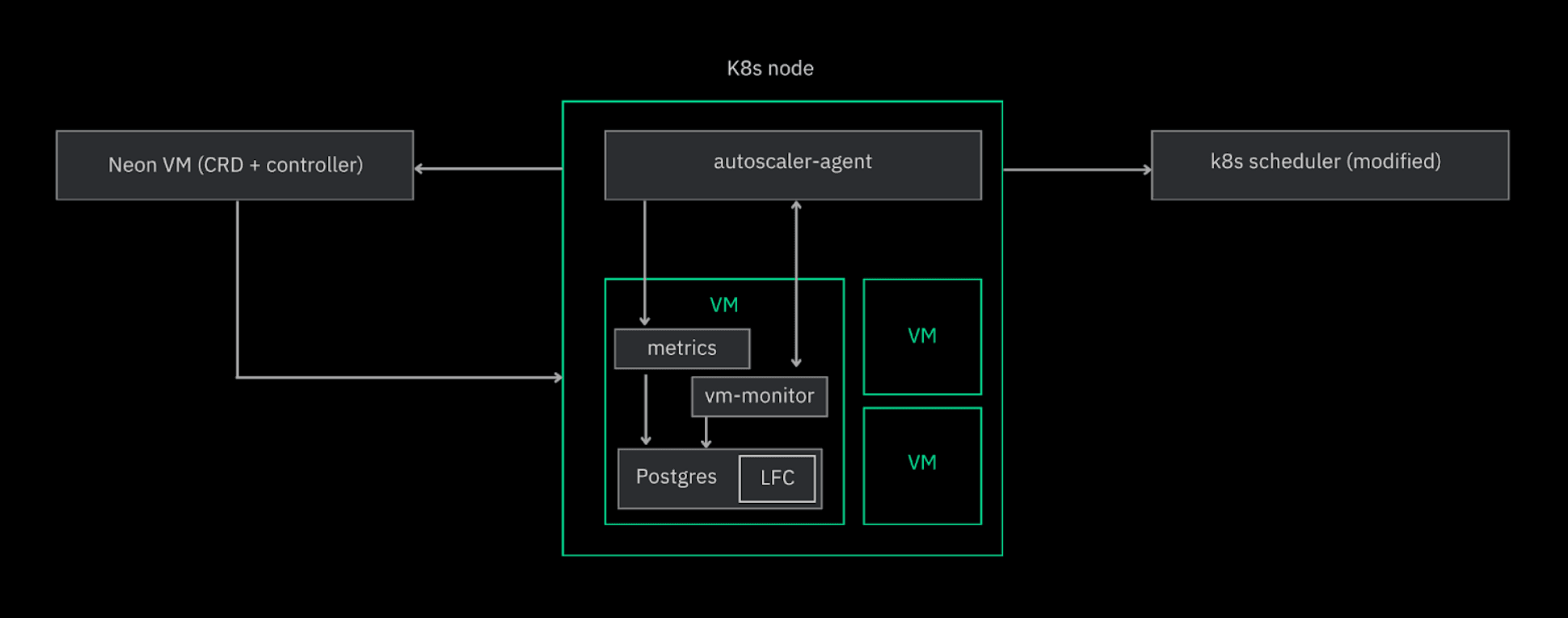
For managing these VMs within Kubernetes, we developed NeonVM to address the lack of native VM support in Kubernetes at the time. NeonVM supports live migration, allowing VMs to move between nodes with minimal downtime (a few milliseconds). This means Neon databases can autoscale in milliseconds—there’s no need to wait for VMs to scale up or down.
Each Kubernetes node runs an autoscaler-agent; these agents are the heart of Neon’s autoscaling system. Agents monitor metrics every 5 seconds to make autoscaling decisions for each Postgres VM. The autoscaler-agent ensures resources are allocated (and removed) efficiently, carefully preventing overcommittment and memory shortages. To achieve this level of control, we modified the Kubernetes scheduler to require all upscaling approvals to be pre-approved by the scheduler, ensuring a global view of resource usage.
Scaling memory was a different problem, involving many iterations. Initially, it relied on cgroup signals, particularly the memory.high signal, to trigger upscaling. This method allowed for almost instant notifications when memory usage exceeded a threshold, but it ended up proving too unstable for our needs. (We’ll write a future engineering blog post only on this topic.)
Instead of a signal based approach we polled the Postgres cgroup’s memory usage ourselves every 100ms to predict and respond to imminent memory exhaustion. This approach, although a bit slower, provided the predictability and stability we needed. Additionally, swap space was added to handle rapid memory allocation more efficiently, particularly for workloads like parallel index building in pgvector.
Lastly, to further improve performance during scaling operations, we introduced a cache backed by local disk that acts as a resizable extension of Postgres’ shared buffers. The autoscaler-agent adjusts the LFC (Local file cache) size during scaling operations to keep the working set size inline with memory requirements. We also leverage metrics from the LFC to inform scaling decisions, ensuring that your workload’s working set remains effectively managed within memory, further optimizing performance.
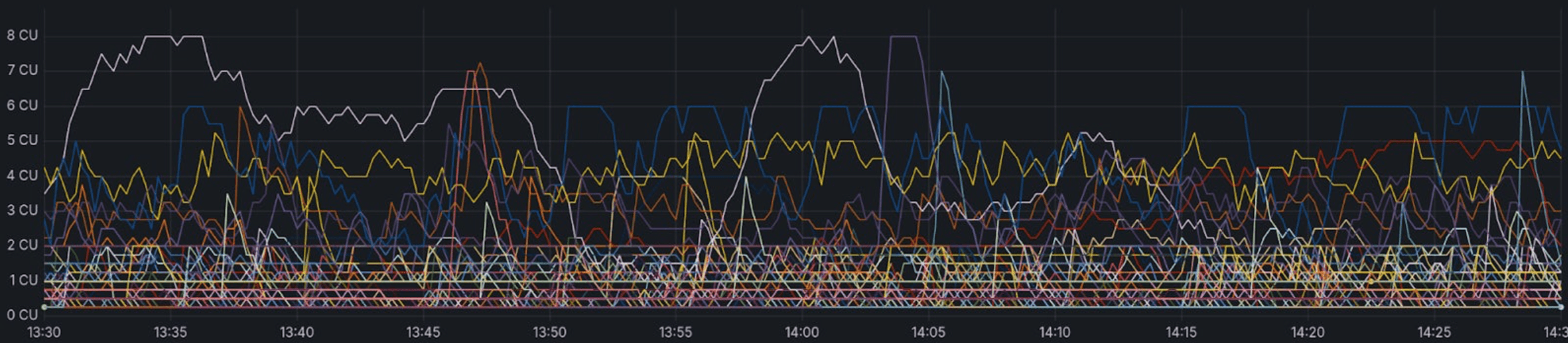
Why autoscaling?
“Our database traffic peaks at nights and on weekends. Building on a database that preemptively autoscales allows us to regularly handle these traffic spikes”
Lex Nasser, Founding Engineer at 222
A core part of Neon’s mission is to make resizing Postgres instances obsolete. Being bound to a specific CPU/RAM config puts developers between a rock and a hard place: unless the database load is incredibly stable and predictable, their choices are: 1) overprovisioning, or 2) manually resizing the instance during traffic spikes, which can lead to unnecessary downtime.
Most modern workloads have some sort of traffic variability. Some applications are more variable than others, but chances are that if you check your database metrics right now and observe a histogram of your provisioned CPU capacity vs the CPU you’ve used, it would fit one of the patterns below:
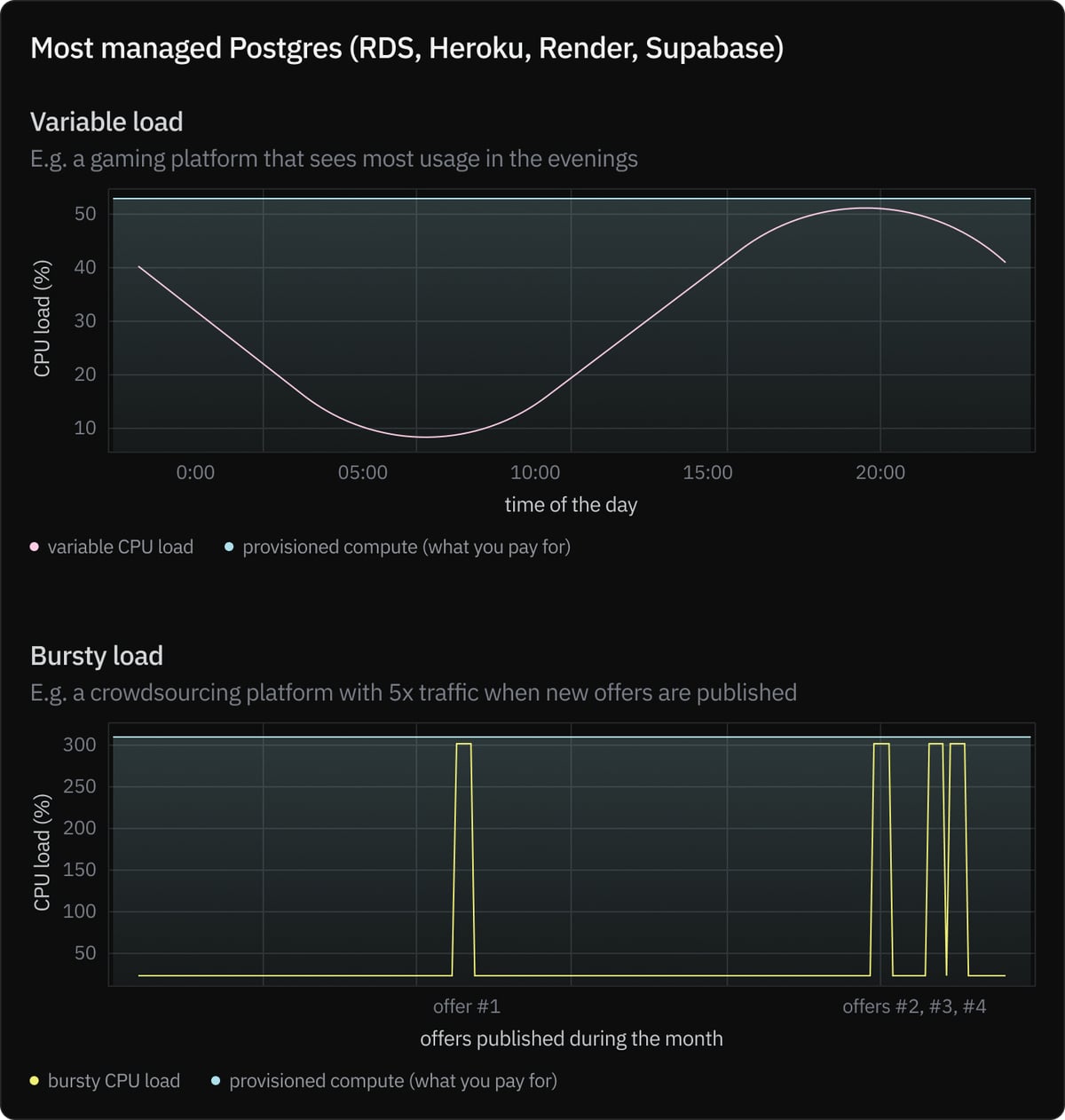
But most hosted Postgres databases run on a combination of EBS/EC2 machines (or Azure VMs / GCE instances). When you’re picking a compute instance size in RDS, you’re simply provisioning an EC2 machine under the hood.
So, in most hosted Postgres, it won’t matter how much compute you are actually consuming. You will be billed by provisioned CPU/memory at the end of the month, even if your metrics show that you only reached peak capacity for a few hours. If you’re running most of the time at 60% capacity, too bad—you’ll still pay for 100% capacity.
Since this is wasteful, you might try to manually resize your instance to add more capacity when needed. But this process often requires some downtime, and it also requires developer time — somebody now has to monitor CPU/memory usage and predict traffic spikes to resize instances in advance.
Overall, the experience is not good—and something we believe can be improved with autoscaling.
“When we were using MySQL in Azure, we had to manually upgrade the database during the days of peak traffic and downgrade later in the day, which caused a couple of minutes of downtime and a huge waste of time for the team”
Pieralberto Colombo, CTO at Recrowd
“Neon perfectly meets our needs for a Postgres solution that scales with demand. We can push the boundaries of what’s possible in our projects without compromising efficiency or costs”
Technical Director at White Widget
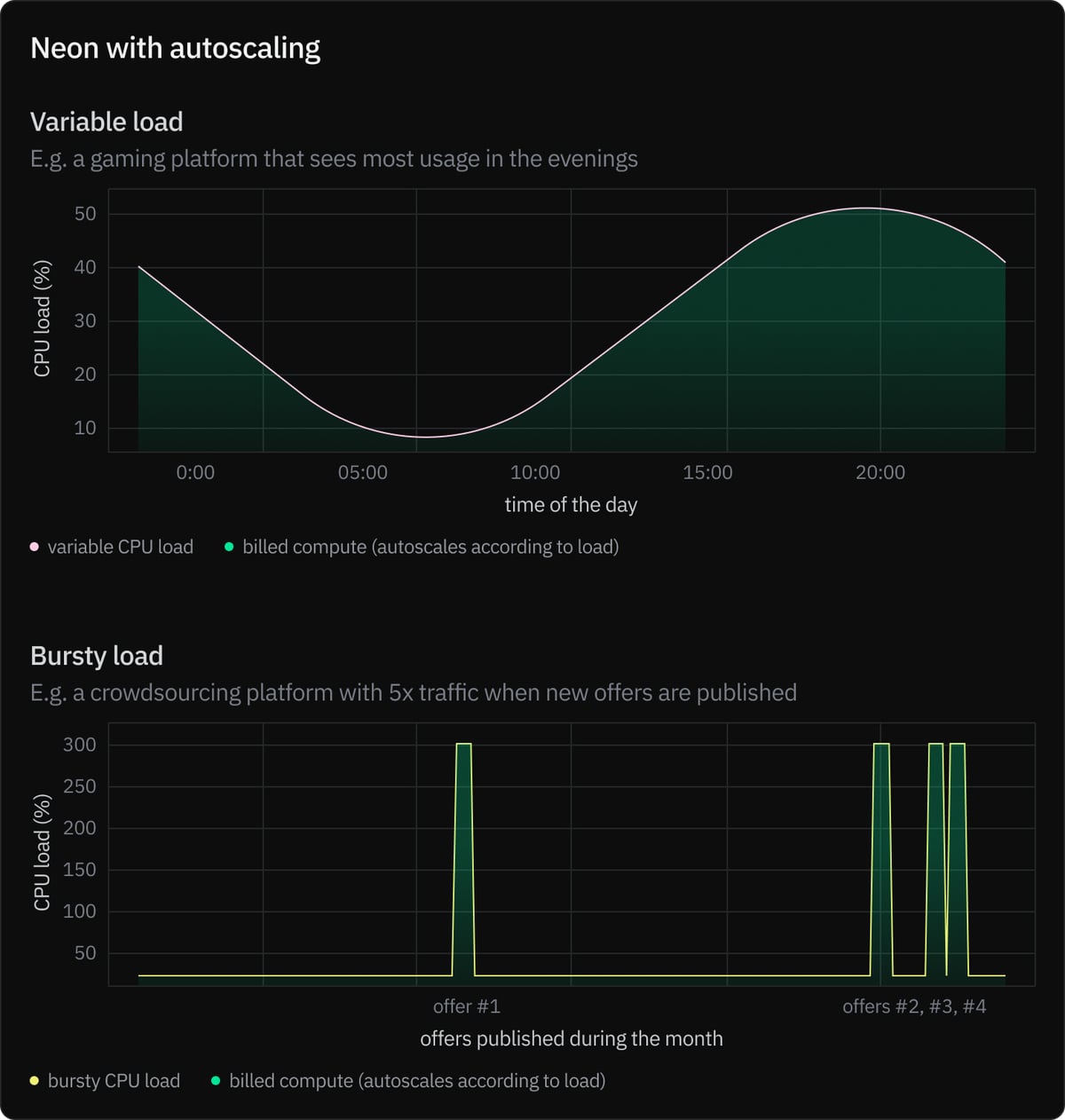
We’ve built Neon autoscaling to offer a better way for Postgres. Instead of provisioning fixed compute, Neon autoscales CPU and memory dynamically up and down in response to load. For cost-control, you define a maximum autoscaling limit. Your Neon database will never scale beyond the max CPU/RAM you set, preventing unexpected charges on your bill.
In addition to a max autoscaling limit, you also define a minimum autoscaling limit, below which your CPU/RAM will never scale down. This allows you to balance costs and performance for your specific needs. A non-production database can scale to zero when not in use, and a production database can maintain a minimum performance level while also being ready to respond to traffic spikes at a moments notice.
Getting started
All Neon databases can now autoscale, including those in the Free plan (up to 2 CPU, 8 GB RAM). To enable autoscaling in your Neon branch, navigate to the Edit compute endpoint menu in the Neon console. Select Enable autoscaling. Use the slider to adjust your minimum and maximum autoscaling limits (e.g. 1 and 6 in the example below). Depending on your pricing plan, you’ll see higher or lower max capacity limits.
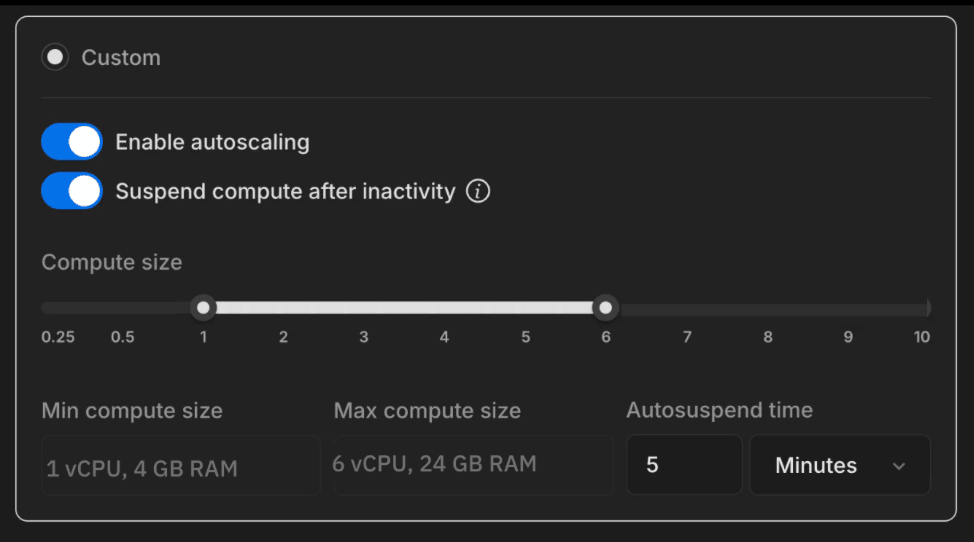
You can also configure autoscaling via the Neon CLI. For example, this command specifies an autoscaling range with a minimum of 0.5 CU and a maximum of 2 CU for the compute in the main branch: neon branches add-compute main --cu 0.5-2
Our configuration advice:
For your production branch (optimizing performance)
- Pick a higher autoscaling limit (e.g. 10 CU)
- Disable scale-to-zero (autosuspend)
For your dev/testing/staging branches (optimizing costs)
- Keep scale-to-zero (autosuspend) enabled
- Pick a lower limit for autoscaling (e.g., 2 CU)

Get started for free
Neon autoscaling brings transparent, open-source autoscaling to all Postgres workloads. If you’re still resizing servers, create a free Neon account and experiment with autoscaling. We want to hear your feedback: join us in Discord and share your experience with the community.