Neon Read Replicas
Scale your app, run ad-hoc queries, and provide read-only access without duplicating data
Neon read replicas are independent computes designed to perform read operations on the same data as your primary read-write compute. Neon's read replicas do not replicate or duplicate data. Instead, read requests are served from the same storage, as shown in the diagram below. While your read-write queries are directed through your primary compute, read queries can be offloaded to one or more read replicas.
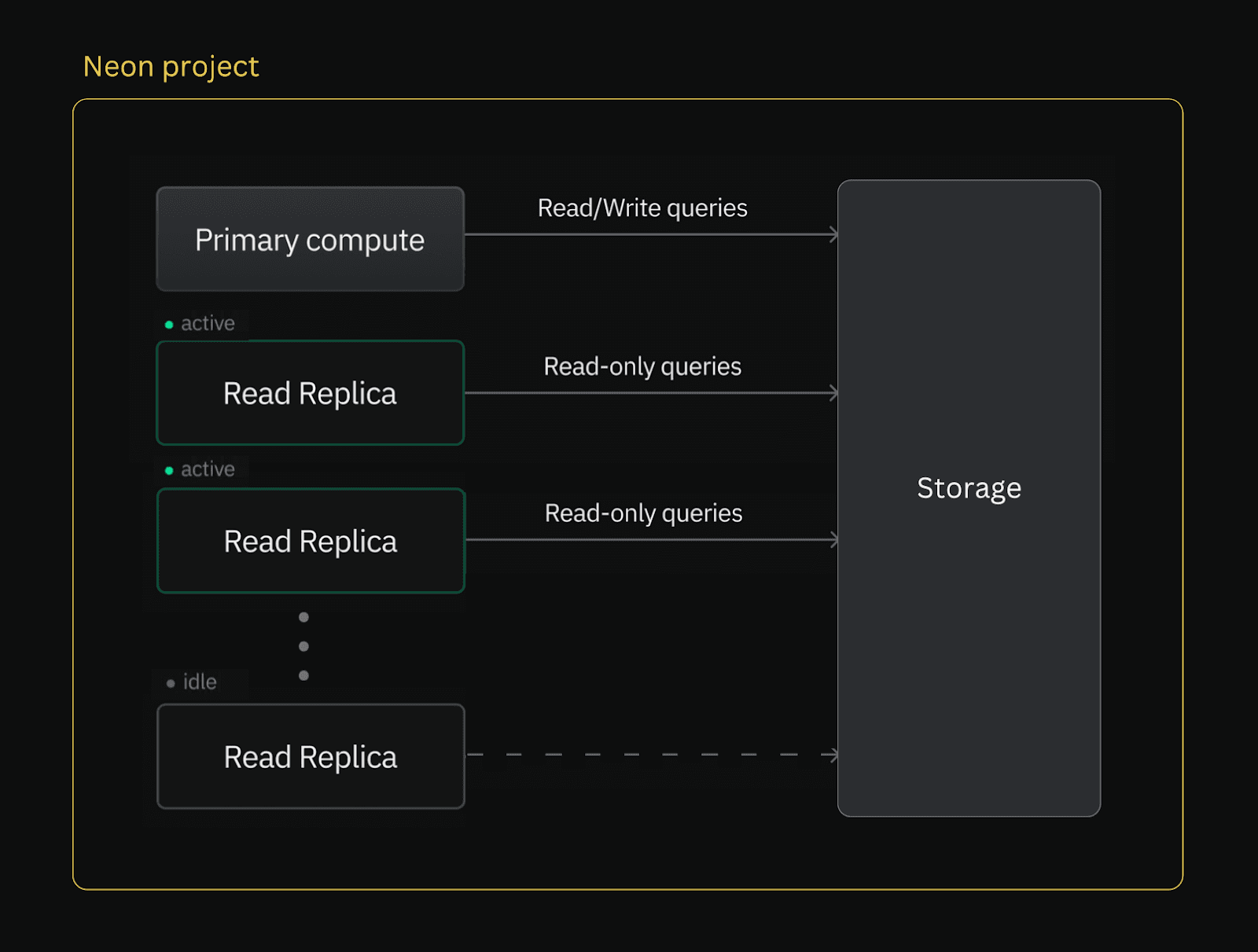
You can instantly create read replicas for any branch in your Neon project and configure the amount of vCPU and memory allocated to each. Read replicas also support Neon's Autoscaling and Autosuspend features, providing you with the same control over compute resources that you have with your primary compute.
How are Neon read replicas different?
- No additional storage is required: With read replicas reading from the same source as your primary read-write compute, no additional storage is required to create a read replica. Data is neither duplicated nor replicated. Creating a read replica involves spinning up a read-only compute instance, which takes a few seconds.
- You can create them almost instantly: With no data replication required, you can create read replicas almost instantly.
- They are cost-efficient: With no additional storage or transfer of data, costs associated with storage and data transfer are avoided. Neon's read replicas also benefit from Neon's Autoscaling and Autosuspend features, which allow you to manage compute usage.
- They are instantly available: You can allow read replicas to scale to zero when not in use without introducing lag. When a read replica starts up in response to a query, it is up to date with your primary read-write compute almost instantly.
How do you create read replicas?
You can create read replicas using the Neon Console, Neon CLI, or Neon API, providing the flexibility required to integrate read replicas into your workflow or CI/CD processes.
From the Neon Console, it's a simple Add Read Replica action on a branch.
note
You can add as many read replicas to a branch as you need, accommodating any scale.
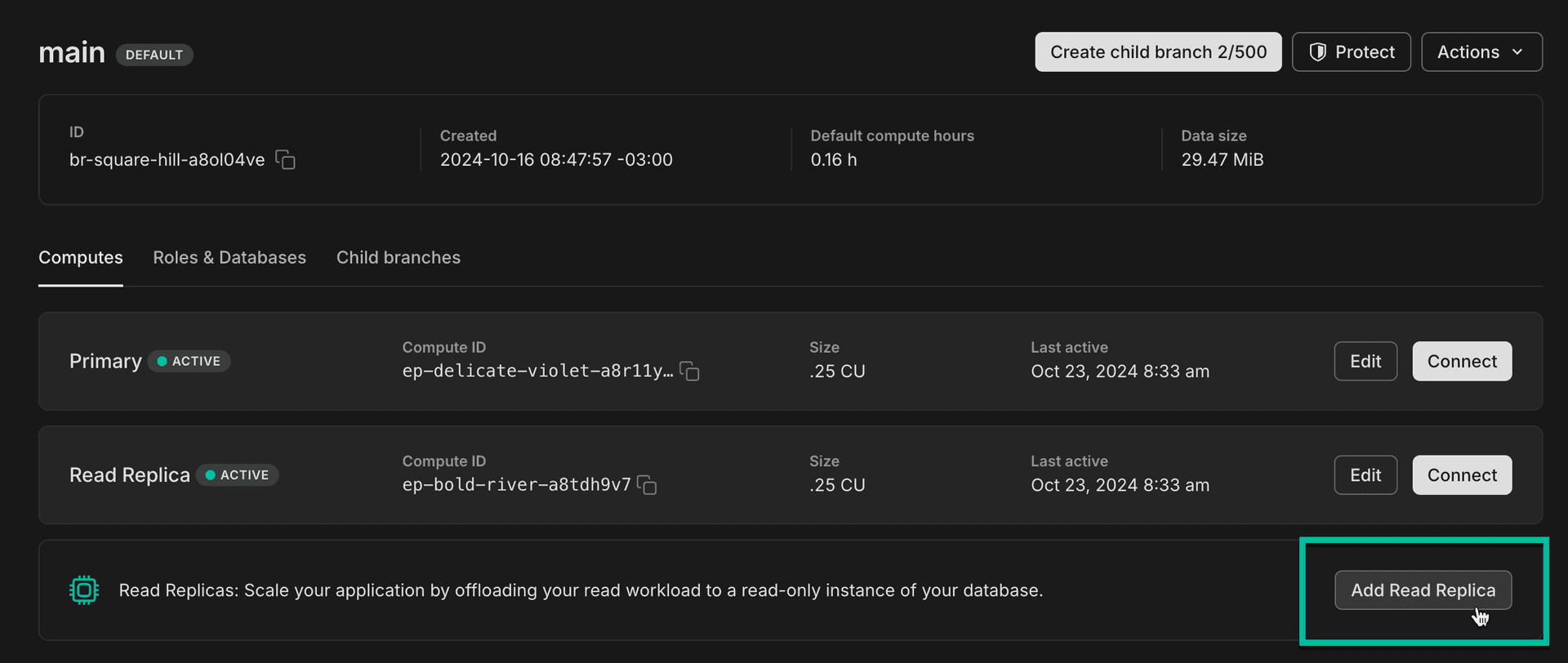
From the CLI or API:
neon branches add-compute mybranch --type read_onlyFor more details and how to connect to a read replica, see Create and manage Read Replicas.
Read Replica architecture
The following diagram shows how your primary compute and read replicas send read requests to the same Pageserver, which is the component of the Neon architecture that is responsible for serving read requests.
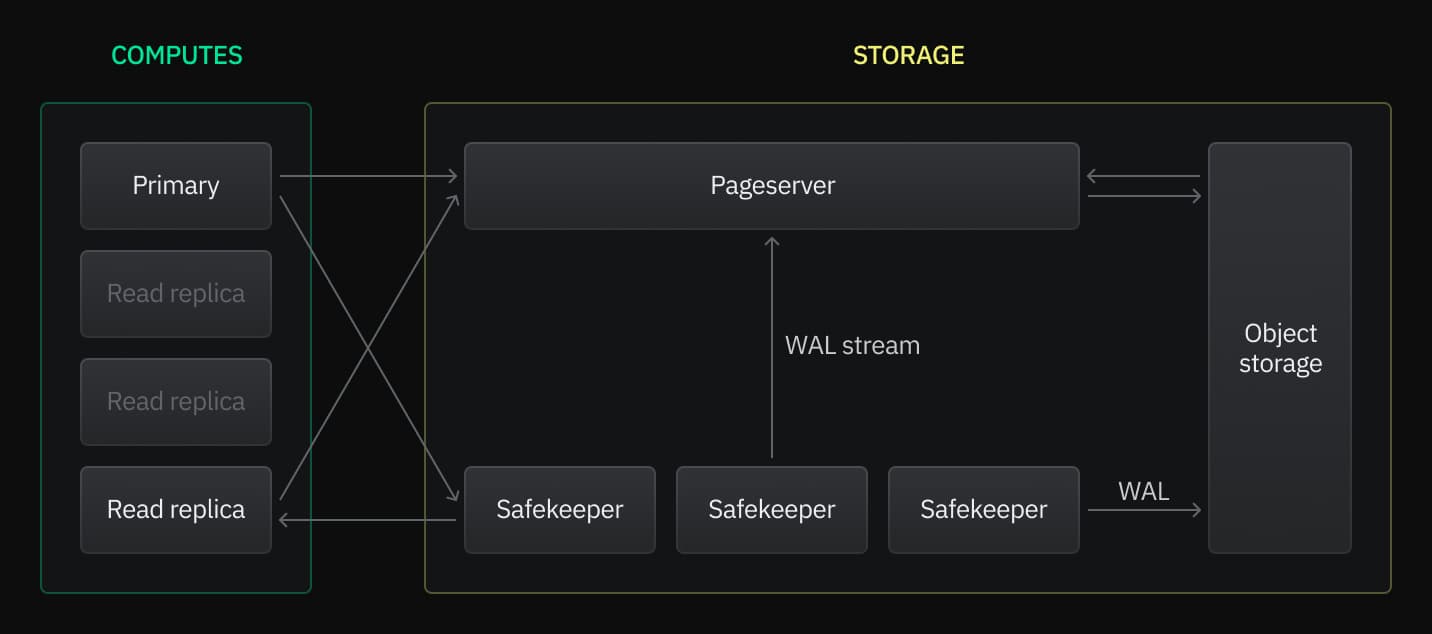
Neon read replicas are asynchronous, which means they are eventually consistent. As updates are made by your primary compute, Safekeepers store the data changes durably until they are processed by Pageservers. At the same time, Safekeepers keep read replica computes up to date with the most recent changes to maintain data consistency.
Neon supports creating read replicas in the same region as your database. Cross-region read replicas are currently not supported.
Use cases
Neon's read replicas have a number of applications:
- Horizontal scaling: Scale your application by distributing read requests across replicas to improve performance and increase throughput.
- Analytics queries: Offloading resource-intensive analytics and reporting workloads to reduce load on the primary compute.
- Read-only access: Granting read-only access to users or applications that don't require write permissions.
Get started with read replicas
To get started with read replicas, refer to our guides:
Create and manage Read Replicas
Learn how to create, connect to, configure, delete, and monitor read replicas
Scale your app with Read Replicas
Scale your app with read replicas using built-in framework support
Run analytics queries with Read Replicas
Leverage read replicas for running data-intensive analytics queries
Run ad-hoc queries with Read Replicas
Leverage read replicas for running ad-hoc queries
Provide read-only access with Read Replicas
Leverage read replicas to provide read-only access to your data